

Beth yw Modelau Iaith Mawr?
Mae Modelau Iaith Mawr (LLMs) yn systemau deallusrwydd artiffisial datblygedig (AI) sydd wedi'u cynllunio i brosesu, deall a chynhyrchu testun tebyg i ddyn. Maent yn seiliedig ar dechnegau dysgu dwfn ac wedi'u hyfforddi ar setiau data enfawr, fel arfer yn cynnwys biliynau o eiriau o ffynonellau amrywiol fel gwefannau, llyfrau, ac erthyglau. Mae'r hyfforddiant helaeth hwn yn galluogi LLMs i ddeall naws iaith, gramadeg, cyd-destun, a hyd yn oed rhai agweddau ar wybodaeth gyffredinol.
Mae rhai LLMs poblogaidd, fel GPT-3 OpenAI, yn defnyddio math o rwydwaith niwral a elwir yn drawsnewidydd, sy'n caniatáu iddynt drin tasgau iaith cymhleth gyda hyfedredd rhyfeddol. Gall y modelau hyn gyflawni ystod eang o dasgau, megis:
- Ateb cwestiynau
- Crynhoi testun
- Cyfieithu ieithoedd
- Cynhyrchu cynnwys
- Hyd yn oed yn cymryd rhan mewn sgyrsiau rhyngweithiol gyda defnyddwyr
Wrth i LLMs barhau i esblygu, mae ganddynt botensial mawr i wella ac awtomeiddio cymwysiadau amrywiol ar draws diwydiannau, o wasanaeth cwsmeriaid a chreu cynnwys i addysg ac ymchwil. Fodd bynnag, maent hefyd yn codi pryderon moesegol a chymdeithasol, megis ymddygiad rhagfarnllyd neu gamddefnydd, y mae angen mynd i'r afael â hwy wrth i dechnoleg ddatblygu.

Enghreifftiau Poblogaidd o Fodelau Iaith Mawr
Dyma rai enghreifftiau amlwg o LLMs a ddefnyddir yn eang mewn gwahanol fertigol diwydiant:
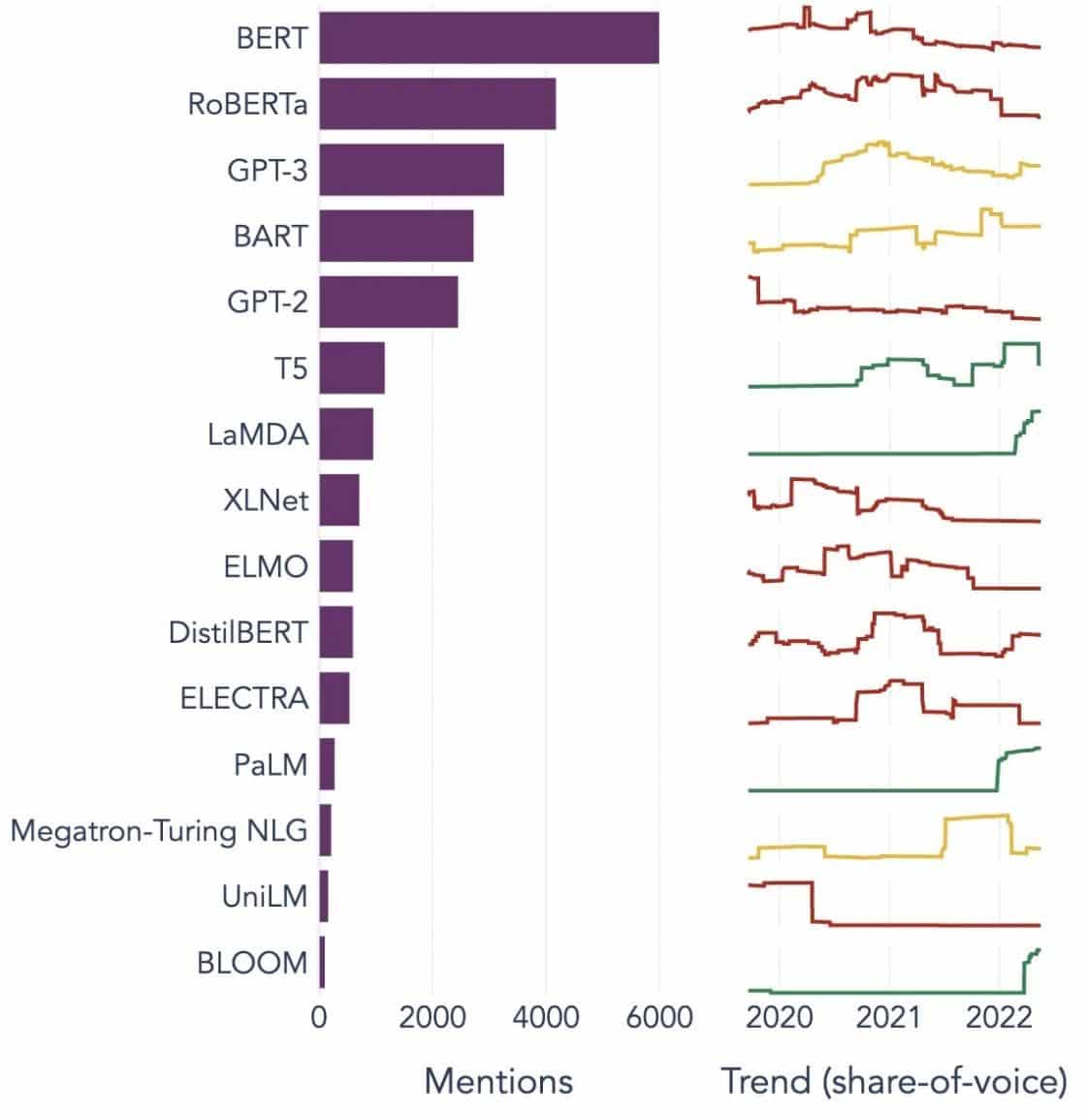
Ffynhonnell Delwedd: Tuag at Wyddoniaeth Data
Sut mae modelau LLM yn cael eu hyfforddi?
Mae hyfforddi modelau iaith mawr (LLMs) yn dipyn o gamp sy'n cynnwys sawl cam hollbwysig. Dyma ddadansoddiad cam-wrth-gam o'r broses wedi'i symleiddio:
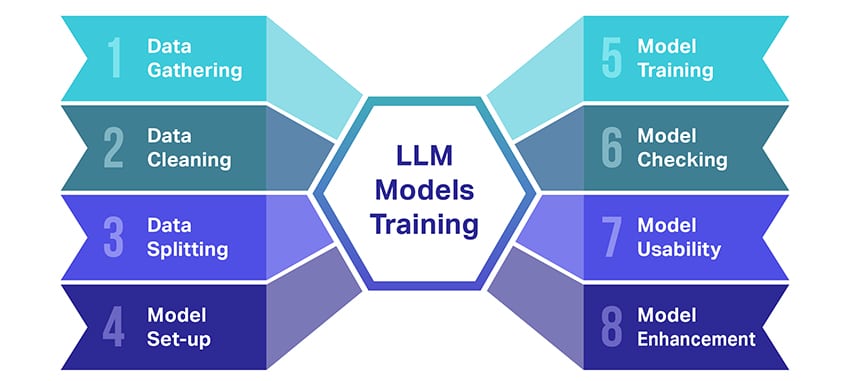
- Casglu Data Testun: Mae hyfforddi LLM yn dechrau gyda chasglu llawer iawn o ddata testun. Gall y data hwn ddod o lyfrau, gwefannau, erthyglau, neu lwyfannau cyfryngau cymdeithasol. Y nod yw dal amrywiaeth gyfoethog iaith ddynol.
- Glanhau'r Data: Yna caiff y data testun crai ei dacluso mewn proses a elwir yn rhagbrosesu. Mae hyn yn cynnwys tasgau fel tynnu nodau diangen, rhannu'r testun yn rhannau llai o'r enw tocynnau, a chael y cyfan i fformat y gall y model weithio gydag ef.
- Rhannu'r Data: Nesaf, rhennir y data glân yn ddwy set. Bydd un set, y data hyfforddi, yn cael ei ddefnyddio i hyfforddi'r model. Defnyddir y set arall, y data dilysu, yn ddiweddarach i brofi perfformiad y model.
- Sefydlu'r Model: Yna caiff strwythur yr LLM, a elwir yn bensaernïaeth, ei ddiffinio. Mae hyn yn cynnwys dewis y math o rwydwaith niwral a phenderfynu ar baramedrau amrywiol, megis nifer yr haenau ac unedau cudd o fewn y rhwydwaith.
- Hyfforddi'r Model: Mae'r hyfforddiant gwirioneddol yn dechrau nawr. Mae'r model LLM yn dysgu trwy edrych ar y data hyfforddi, gwneud rhagfynegiadau yn seiliedig ar yr hyn y mae wedi'i ddysgu hyd yn hyn, ac yna addasu ei baramedrau mewnol i leihau'r gwahaniaeth rhwng ei ragfynegiadau a'r data gwirioneddol.
- Gwirio'r Model: Mae dysgu'r model LLM yn cael ei wirio gan ddefnyddio'r data dilysu. Mae hyn yn helpu i weld pa mor dda y mae'r model yn perfformio ac i addasu gosodiadau'r model ar gyfer perfformiad gwell.
- Defnyddio'r Model: Ar ôl hyfforddi a gwerthuso, mae'r model LLM yn barod i'w ddefnyddio. Bellach gellir ei integreiddio i raglenni neu systemau lle bydd yn cynhyrchu testun yn seiliedig ar fewnbynnau newydd a roddir.
- Gwella'r Model: Yn olaf, mae lle i wella bob amser. Gellir mireinio'r model LLM ymhellach dros amser, gan ddefnyddio data wedi'i ddiweddaru neu addasu gosodiadau yn seiliedig ar adborth a defnydd yn y byd go iawn.
Cofiwch, mae'r broses hon yn gofyn am adnoddau cyfrifiadurol sylweddol, megis unedau prosesu pwerus a storfa fawr, yn ogystal â gwybodaeth arbenigol mewn dysgu peiriannau. Dyna pam y caiff ei wneud fel arfer gan sefydliadau ymchwil penodol neu gwmnïau sydd â mynediad at y seilwaith a'r arbenigedd angenrheidiol.
A yw'r LLM yn Dibynnu ar Ddysgu Dan Oruchwyliaeth neu Ddysgu Heb Oruchwyliaeth?
Fel arfer caiff modelau iaith mawr eu hyfforddi gan ddefnyddio dull a elwir yn ddysgu dan oruchwyliaeth. Yn syml, mae hyn yn golygu eu bod yn dysgu o enghreifftiau sy'n dangos yr atebion cywir iddynt.
 Dychmygwch eich bod chi'n dysgu geiriau plentyn trwy ddangos lluniau iddyn nhw. Rydych chi'n dangos llun o gath iddyn nhw ac yn dweud “cath,” ac maen nhw'n dysgu cysylltu'r llun hwnnw â'r gair. Dyna sut mae dysgu dan oruchwyliaeth yn gweithio. Rhoddir llawer o destun i'r model (y “lluniau”) a'r allbynnau cyfatebol (y “geiriau”), ac mae'n dysgu eu paru.
Dychmygwch eich bod chi'n dysgu geiriau plentyn trwy ddangos lluniau iddyn nhw. Rydych chi'n dangos llun o gath iddyn nhw ac yn dweud “cath,” ac maen nhw'n dysgu cysylltu'r llun hwnnw â'r gair. Dyna sut mae dysgu dan oruchwyliaeth yn gweithio. Rhoddir llawer o destun i'r model (y “lluniau”) a'r allbynnau cyfatebol (y “geiriau”), ac mae'n dysgu eu paru.
Felly, os ydych chi'n bwydo brawddeg i LLM, mae'n ceisio rhagweld y gair neu'r ymadrodd nesaf yn seiliedig ar yr hyn y mae wedi'i ddysgu o'r enghreifftiau. Fel hyn, mae'n dysgu sut i gynhyrchu testun sy'n gwneud synnwyr ac yn cyd-fynd â'r cyd-destun.
Wedi dweud hynny, weithiau mae LLMs hefyd yn defnyddio ychydig o ddysgu heb oruchwyliaeth. Mae hyn fel gadael i'r plentyn archwilio ystafell yn llawn o wahanol deganau a dysgu amdanynt ar eu pen eu hunain. Mae’r model yn edrych ar ddata heb ei labelu, patrymau dysgu, a strwythurau heb gael gwybod yr atebion “cywir”.
Mae dysgu dan oruchwyliaeth yn defnyddio data sydd wedi'i labelu â mewnbynnau ac allbynnau, yn wahanol i ddysgu heb oruchwyliaeth, nad yw'n defnyddio data allbwn wedi'i labelu.
Yn gryno, caiff LLMs eu hyfforddi'n bennaf gan ddefnyddio dysgu dan oruchwyliaeth, ond gallant hefyd ddefnyddio dysgu heb oruchwyliaeth i wella eu galluoedd, megis ar gyfer dadansoddi archwiliadol a lleihau dimensioldeb.
Beth Yw'r Cyfaint Data (Ym Mhrydain Fawr) Sy'n Angenrheidiol I Hyfforddi Model Iaith Mawr?
Mae byd y posibiliadau ar gyfer adnabod data lleferydd a chymwysiadau llais yn aruthrol, ac maent yn cael eu defnyddio mewn sawl diwydiant ar gyfer llu o gymwysiadau.
Nid yw hyfforddi model iaith mawr yn broses un maint i bawb, yn enwedig o ran y data sydd ei angen. Mae'n dibynnu ar griw o bethau:
- Dyluniad y model.
- Pa waith sydd angen iddo ei wneud?
- Y math o ddata rydych chi'n ei ddefnyddio.
- Pa mor dda ydych chi am iddo berfformio?
Wedi dweud hynny, mae hyfforddi LLMs fel arfer yn gofyn am lawer iawn o ddata testun. Ond pa mor enfawr ydyn ni'n siarad amdano? Wel, meddyliwch ymhell y tu hwnt i gigabeit (GB). Fel arfer rydym yn edrych ar terabytes (TB) neu hyd yn oed petabytes (PB) o ddata.
Ystyriwch GPT-3, un o'r LLMs mwyaf o gwmpas. Mae'n cael ei hyfforddi ar 570 GB o ddata testun. Efallai y bydd angen llai ar LLMs llai - efallai 10-20 GB neu hyd yn oed 1 GB o gigabeit - ond mae'n dal i fod yn llawer.

Ond nid yw'n ymwneud â maint y data yn unig. Mae ansawdd yn bwysig hefyd. Mae angen i'r data fod yn lân ac yn amrywiol er mwyn helpu'r model i ddysgu'n effeithiol. Ac ni allwch anghofio am ddarnau allweddol eraill o'r pos, fel y pŵer cyfrifiadurol sydd ei angen arnoch, yr algorithmau rydych chi'n eu defnyddio ar gyfer hyfforddiant, a'r gosodiad caledwedd sydd gennych. Mae'r holl ffactorau hyn yn chwarae rhan fawr mewn hyfforddi LLM.
Cynnydd Modelau Iaith Mawr: Pam Maen nhw'n Bwysig
Nid cysyniad neu arbrawf yn unig yw LLMs mwyach. Maent yn chwarae rhan hanfodol gynyddol yn ein tirwedd ddigidol. Ond pam mae hyn yn digwydd? Beth sy'n gwneud y LLMs hyn mor bwysig? Gadewch i ni ymchwilio i rai ffactorau allweddol.
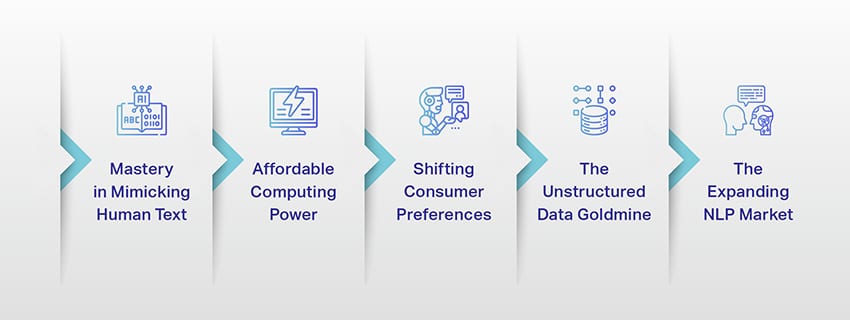
Meistrolaeth mewn Dynwared Testun Dynol
Mae LLMs wedi trawsnewid y ffordd yr ydym yn ymdrin â thasgau sy'n seiliedig ar iaith. Wedi'u hadeiladu gan ddefnyddio algorithmau dysgu peirianyddol cadarn, mae gan y modelau hyn y gallu i ddeall naws iaith ddynol, gan gynnwys cyd-destun, emosiwn, a hyd yn oed coegni, i ryw raddau. Nid newydd-deb yn unig yw'r gallu hwn i ddynwared iaith ddynol, mae iddo oblygiadau sylweddol.
Gall galluoedd cynhyrchu testun uwch LLMs wella popeth o greu cynnwys i ryngweithio gwasanaeth cwsmeriaid.
Dychmygwch allu gofyn cwestiwn cymhleth i gynorthwyydd digidol a chael ateb sydd nid yn unig yn gwneud synnwyr, ond sydd hefyd yn gydlynol, yn berthnasol, ac yn cael ei gyflwyno mewn naws sgwrsio. Dyna beth mae LLMs yn ei alluogi. Maen nhw'n hybu rhyngweithiad dynol-peiriant mwy greddfol a deniadol, gan gyfoethogi profiadau defnyddwyr, a democrateiddio mynediad at wybodaeth.
Pŵer Cyfrifiadura Fforddiadwy
Ni fyddai cynnydd LLMs wedi bod yn bosibl heb ddatblygiadau cyfochrog ym maes cyfrifiadura. Yn fwy penodol, mae democrateiddio adnoddau cyfrifiannol wedi chwarae rhan arwyddocaol yn esblygiad a mabwysiadu LLMs.
Mae llwyfannau cwmwl yn cynnig mynediad digynsail i adnoddau cyfrifiadura perfformiad uchel. Fel hyn, gall hyd yn oed sefydliadau bach ac ymchwilwyr annibynnol hyfforddi modelau dysgu peirianyddol soffistigedig.
At hynny, mae gwelliannau mewn unedau prosesu (fel GPUs a TPUs), ynghyd â chynnydd mewn cyfrifiadura gwasgaredig, wedi ei gwneud hi'n ymarferol hyfforddi modelau gyda biliynau o baramedrau. Mae hygyrchedd cynyddol pŵer cyfrifiadura yn galluogi twf a llwyddiant LLMs, gan arwain at fwy o arloesi a chymwysiadau yn y maes.
Newid Dewisiadau Defnyddwyr
Nid atebion yn unig sydd eu heisiau ar ddefnyddwyr heddiw; maent eisiau rhyngweithiadau atyniadol a chyfnewidiadwy. Wrth i fwy o bobl dyfu i fyny gan ddefnyddio technoleg ddigidol, mae'n amlwg bod yr angen am dechnoleg sy'n teimlo'n fwy naturiol a dynol yn cynyddu. Mae LLMs yn cynnig cyfle heb ei ail i fodloni'r disgwyliadau hyn. Trwy gynhyrchu testun tebyg i ddyn, gall y modelau hyn greu profiadau digidol deniadol a deinamig, a all gynyddu boddhad a theyrngarwch defnyddwyr. Boed yn chatbots AI sy'n darparu gwasanaeth cwsmeriaid neu gynorthwywyr llais yn darparu diweddariadau newyddion, mae LLMs yn tywys mewn oes o AI sy'n ein deall yn well.
Mwynglawdd Aur Data Anstrwythuredig
Mae data anstrwythuredig, fel e-byst, postiadau cyfryngau cymdeithasol, ac adolygiadau cwsmeriaid, yn drysorfa o fewnwelediadau. Amcangyfrifir bod drosodd 80% o ddata menter yn anstrwythuredig ac yn tyfu ar gyfradd o 55% y flwyddyn. Mae'r data hwn yn fwynglawdd aur i fusnesau os caiff ei ddefnyddio'n iawn.
Mae LLMs yn dod i rym yma, gyda'u gallu i brosesu a gwneud synnwyr o ddata o'r fath ar raddfa. Gallant drin tasgau fel dadansoddi teimladau, dosbarthu testun, echdynnu gwybodaeth, a mwy, a thrwy hynny ddarparu mewnwelediadau gwerthfawr.
P'un a yw'n nodi tueddiadau o bostiadau cyfryngau cymdeithasol neu'n mesur teimladau cwsmeriaid o adolygiadau, mae LLMs yn helpu busnesau i lywio'r swm mawr o ddata anstrwythuredig a gwneud penderfyniadau sy'n seiliedig ar ddata.
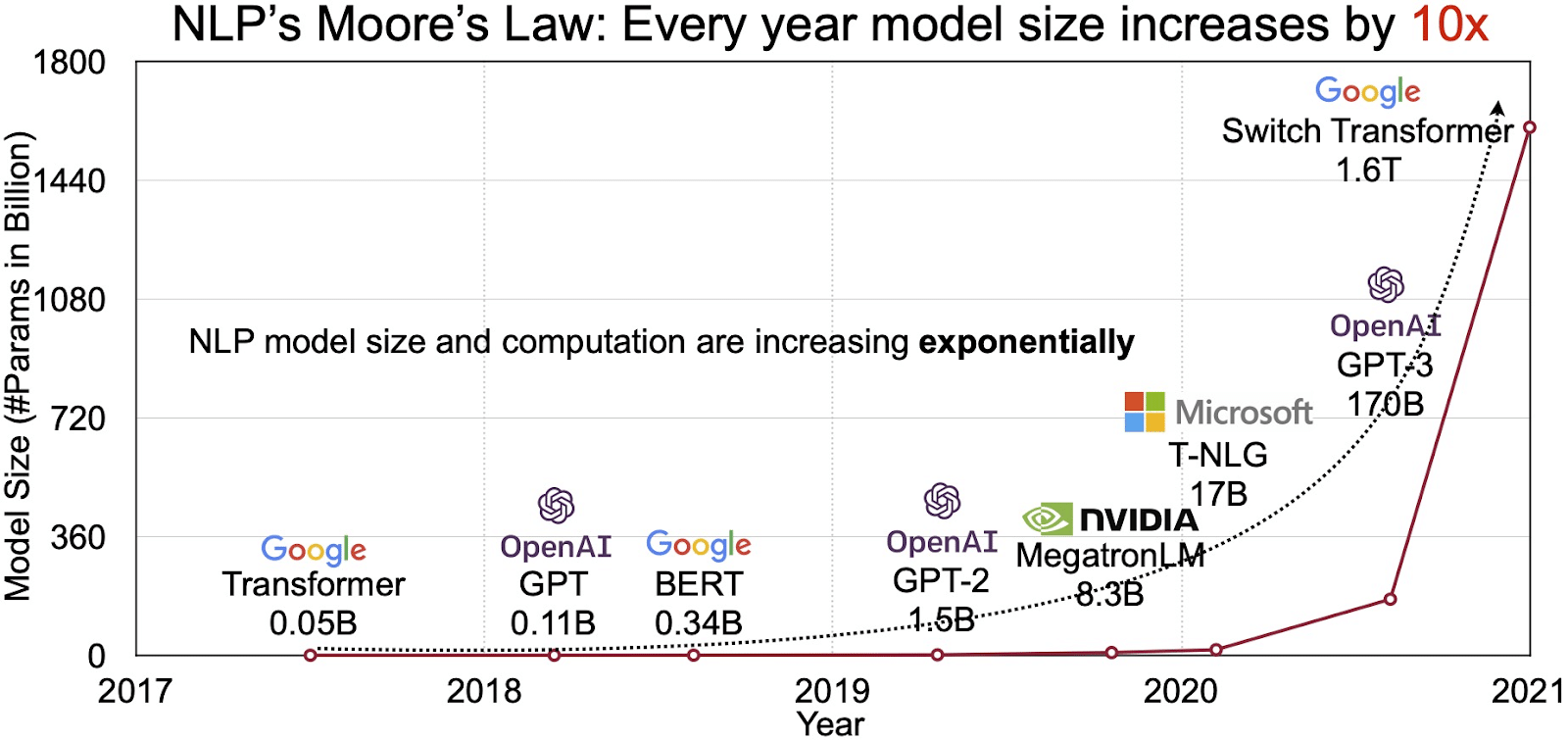
Y Farchnad NLP sy'n Ehangu
Adlewyrchir potensial LLMs yn y farchnad sy'n tyfu'n gyflym ar gyfer prosesu iaith naturiol (NLP). Mae dadansoddwyr yn rhagamcanu'r farchnad NLP i ehangu ohoni $11 biliwn yn 2020 i dros $35 biliwn erbyn 2026. Ond nid maint y farchnad yn unig sy'n ehangu. Mae'r modelau eu hunain yn tyfu hefyd, o ran maint corfforol ac yn nifer y paramedrau y maent yn eu trin. Mae esblygiad LLMs dros y blynyddoedd, fel y gwelir yn y ffigwr isod (ffynhonnell delwedd: cyswllt), yn tanlinellu eu cymhlethdod a’u gallu cynyddol.
Achosion Defnydd Poblogaidd o Fodelau Iaith Mawr
Dyma rai o'r achosion defnydd uchaf a mwyaf cyffredin o LLM:
- Cynhyrchu Testun Iaith Naturiol: Mae Modelau Iaith Mawr (LLMs) yn cyfuno pŵer deallusrwydd artiffisial ac ieithyddiaeth gyfrifiadol i gynhyrchu testunau mewn iaith naturiol yn annibynnol. Gallant ddarparu ar gyfer anghenion defnyddwyr amrywiol megis ysgrifennu erthyglau, crefftio caneuon, neu gymryd rhan mewn sgyrsiau â defnyddwyr.
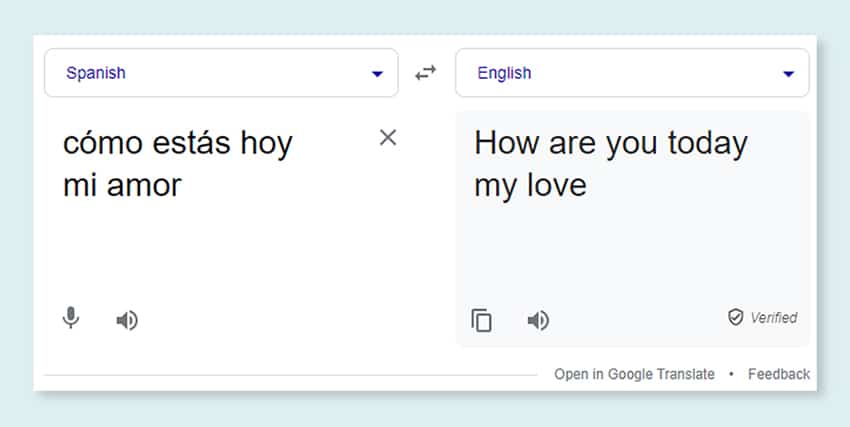
- Cyfieithu trwy Beiriannau: Gellir defnyddio LLMs yn effeithiol i gyfieithu testun rhwng unrhyw bâr o ieithoedd. Mae'r modelau hyn yn manteisio ar algorithmau dysgu dwfn fel rhwydweithiau niwral rheolaidd i ddeall strwythur ieithyddol yr iaith ffynhonnell a'r iaith darged, a thrwy hynny hwyluso cyfieithu'r testun ffynhonnell i'r iaith a ddymunir.
- Creu Cynnwys Gwreiddiol: Mae LLMs wedi agor llwybrau i beiriannau gynhyrchu cynnwys cydlynol a rhesymegol. Gellir defnyddio'r cynnwys hwn i greu postiadau blog, erthyglau, a mathau eraill o gynnwys. Mae'r modelau'n manteisio ar eu profiad dysgu dwfn dwys i fformatio a strwythuro'r cynnwys mewn modd newydd a hawdd ei ddefnyddio.
- Dadansoddi Teimladau: Un cymhwysiad diddorol o Fodelau Iaith Mawr yw dadansoddi teimladau. Yn hyn o beth, mae'r model wedi'i hyfforddi i adnabod a chategoreiddio cyflyrau a theimladau emosiynol sy'n bresennol yn y testun anodedig. Gall y meddalwedd nodi emosiynau fel positifrwydd, negyddoldeb, niwtraliaeth, a theimladau cymhleth eraill. Gall hyn roi mewnwelediad gwerthfawr i adborth cwsmeriaid a barn am wahanol gynhyrchion a gwasanaethau.
- Deall, Crynhoi a Dosbarthu Testun: Mae LLMs yn sefydlu strwythur hyfyw ar gyfer meddalwedd deallusrwydd artiffisial i ddehongli'r testun a'i gyd-destun. Trwy gyfarwyddo'r model i ddeall a chraffu ar symiau enfawr o ddata, mae LLMs yn galluogi modelau AI i ddeall, crynhoi, a hyd yn oed gategoreiddio testun mewn ffurfiau a phatrymau amrywiol.
- Ateb Cwestiynau: Mae Modelau Iaith Mawr yn rhoi'r gallu i systemau Ateb Cwestiynau (SA) ganfod ac ymateb yn gywir i ymholiad iaith naturiol defnyddiwr. Mae enghreifftiau poblogaidd o'r achos defnydd hwn yn cynnwys ChatGPT a BERT, sy'n archwilio cyd-destun ymholiad a sifftio trwy gasgliad helaeth o destunau i ddarparu ymatebion perthnasol i gwestiynau defnyddwyr.

Tagio Rhan-o-Leferydd (POS).
Mae geiriau mewn brawddegau yn cael eu tagio gyda'u swyddogaeth ramadegol, megis berfau, enwau, ansoddeiriau, ac ati. Mae'r broses hon yn cynorthwyo'r model i ddeall y gramadeg a'r cysylltiadau rhwng geiriau.

Cydnabod Endid a Enwyd (NER)
Mae endidau a enwir fel sefydliadau, lleoliadau, a phobl o fewn brawddeg yn cael eu marcio. Mae'r ymarfer hwn yn cynorthwyo'r model i ddehongli ystyr semantig geiriau ac ymadroddion ac yn darparu ymatebion mwy manwl gywir.

Dadansoddiad Sentiment
Rhoddir labeli teimlad fel cadarnhaol, niwtral neu negyddol i ddata testun, gan helpu'r model i ddeall tanlinell emosiynol brawddegau. Mae'n arbennig o ddefnyddiol wrth ymateb i ymholiadau sy'n ymwneud ag emosiynau a barn.
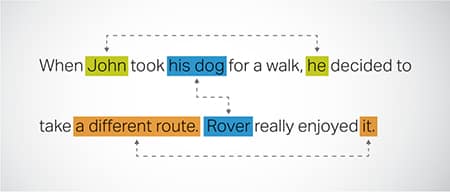
Cydsyniad Craidd
Nodi a datrys achosion lle cyfeirir at yr un endid mewn gwahanol rannau o destun. Mae'r cam hwn yn helpu'r model i ddeall cyd-destun y frawddeg, gan arwain at ymatebion cydlynol.
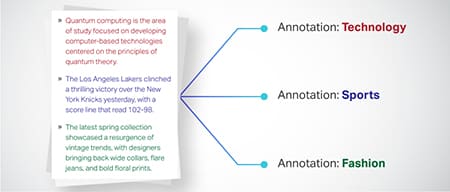
Dosbarthiad Testun
Mae data testun yn cael ei gategoreiddio i grwpiau wedi'u diffinio ymlaen llaw fel adolygiadau cynnyrch neu erthyglau newyddion. Mae hyn yn cynorthwyo'r model i ganfod genre neu destun y testun, gan gynhyrchu ymatebion mwy perthnasol.
Offrwm Shaip
Shaip yn cynnig ystod eang o wasanaethau i helpu sefydliadau i reoli, dadansoddi a gwneud y gorau o’u data.
Sgrapio Gwe Data
Un gwasanaeth allweddol a gynigir gan Shaip yw crafu data. Mae hyn yn cynnwys echdynnu data o URLau parth-benodol. Trwy ddefnyddio offer a thechnegau awtomataidd, gall Shaip sgrapio symiau mawr o ddata yn gyflym ac yn effeithlon o wefannau amrywiol, Llawlyfrau Cynnyrch, Dogfennaeth Dechnegol, Fforymau Ar-lein, Adolygiadau Ar-lein, Data Gwasanaeth Cwsmeriaid, Dogfennau Rheoleiddio'r Diwydiant ac ati. Gall y broses hon fod yn amhrisiadwy i fusnesau pan fydd casglu data perthnasol a phenodol o amrywiaeth o ffynonellau.

Cyfieithu Peiriant
Datblygu modelau gan ddefnyddio setiau data amlieithog helaeth ynghyd â thrawsgrifiadau cyfatebol ar gyfer cyfieithu testun ar draws amrywiol ieithoedd. Mae'r broses hon yn helpu i ddatgymalu rhwystrau ieithyddol ac yn hyrwyddo hygyrchedd gwybodaeth.
Echdynnu a Chreu Tacsonomeg
Gall Shaip helpu gydag echdynnu tacsonomeg a chreu. Mae hyn yn cynnwys dosbarthu a chategoreiddio data i fformat strwythuredig sy'n adlewyrchu'r perthnasoedd rhwng gwahanol bwyntiau data. Gall hyn fod yn arbennig o ddefnyddiol i fusnesau wrth drefnu eu data, gan ei wneud yn fwy hygyrch ac yn haws ei ddadansoddi. Er enghraifft, mewn busnes e-fasnach, gellir categoreiddio data cynnyrch yn seiliedig ar y math o gynnyrch, brand, pris, ac ati, gan ei gwneud hi'n haws i gwsmeriaid lywio'r catalog cynnyrch.
Casglu data
Mae ein gwasanaethau casglu data yn darparu data byd go iawn neu synthetig hanfodol sy'n angenrheidiol ar gyfer hyfforddi algorithmau AI cynhyrchiol a gwella cywirdeb ac effeithiolrwydd eich modelau. Mae'r data yn ddiduedd, yn foesegol ac yn gyfrifol wrth gadw preifatrwydd a diogelwch data mewn cof.

Holi ac Ateb
Mae ateb cwestiynau (SA) yn is-faes o brosesu iaith naturiol sy'n canolbwyntio ar ateb cwestiynau yn awtomatig mewn iaith ddynol. Mae systemau SA wedi'u hyfforddi ar destun a chod helaeth, gan eu galluogi i drin gwahanol fathau o gwestiynau, gan gynnwys cwestiynau ffeithiol, diffiniadol a rhai sy'n seiliedig ar farn. Mae gwybodaeth parth yn hanfodol ar gyfer datblygu modelau SA wedi'u teilwra i feysydd penodol fel cymorth cwsmeriaid, gofal iechyd, neu gadwyn gyflenwi. Fodd bynnag, mae dulliau sicrhau ansawdd cynhyrchiol yn galluogi modelau i gynhyrchu testun heb wybodaeth parth, gan ddibynnu ar y cyd-destun yn unig.
Gall ein tîm o arbenigwyr astudio dogfennau neu lawlyfrau cynhwysfawr yn fanwl i gynhyrchu parau Cwestiwn-Ateb, gan hwyluso creu AI Generative ar gyfer busnesau. Gall y dull hwn fynd i'r afael ag ymholiadau defnyddwyr yn effeithiol trwy gloddio gwybodaeth berthnasol o gorpws helaeth. Mae ein harbenigwyr ardystiedig yn sicrhau cynhyrchu parau Holi ac Ateb o ansawdd uchel sy'n rhychwantu pynciau a pharthau amrywiol.

Crynhoad Testun
Mae ein harbenigwyr yn gallu distyllu sgyrsiau cynhwysfawr neu ddeialogau hir, gan gyflwyno crynodebau cryno a chraff o ddata testun helaeth.

Cynhyrchu Testun
Hyfforddwch fodelau gan ddefnyddio set ddata eang o destun mewn arddulliau amrywiol, fel erthyglau newyddion, ffuglen a barddoniaeth. Yna gall y modelau hyn gynhyrchu gwahanol fathau o gynnwys, gan gynnwys darnau newyddion, cofnodion blog, neu bostiadau cyfryngau cymdeithasol, gan gynnig datrysiad cost-effeithiol sy'n arbed amser ar gyfer creu cynnwys.
Cydnabyddiaeth Araith
Datblygu modelau sy'n gallu deall iaith lafar ar gyfer cymwysiadau amrywiol. Mae hyn yn cynnwys cynorthwywyr sy'n cael eu hysgogi gan lais, meddalwedd arddweud, ac offer cyfieithu amser real. Mae'r broses yn cynnwys defnyddio set ddata gynhwysfawr sy'n cynnwys recordiadau sain o'r iaith lafar, ynghyd â'u trawsgrifiadau cyfatebol.

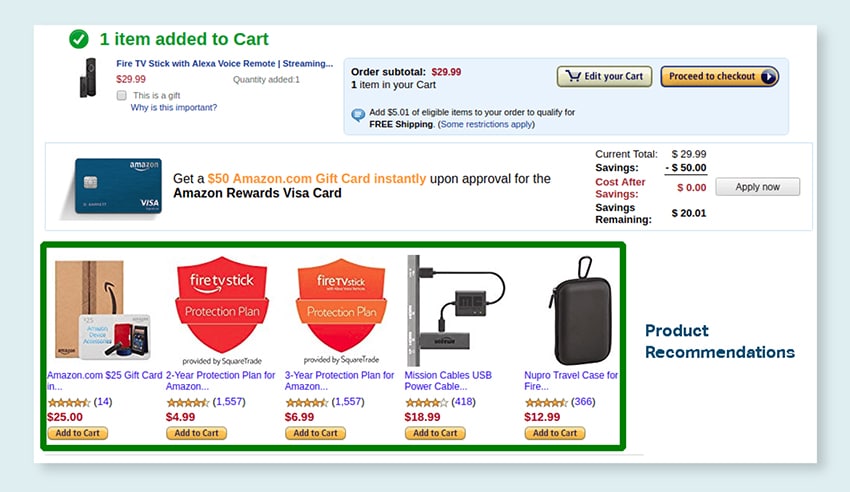
Argymhellion Cynnyrch
Datblygu modelau gan ddefnyddio setiau data helaeth o hanes prynu cwsmeriaid, gan gynnwys labeli sy'n nodi'r cynhyrchion y mae cwsmeriaid yn dueddol o'u prynu. Y nod yw darparu awgrymiadau manwl gywir i gwsmeriaid, a thrwy hynny hybu gwerthiant a gwella boddhad cwsmeriaid.
Pennawd Delwedd
Chwyldroadwch eich proses dehongli delwedd gyda'n gwasanaeth Capsiynau Delwedd o'r radd flaenaf sy'n cael ei yrru gan AI. Rydym yn trwytho bywiogrwydd i luniau trwy gynhyrchu disgrifiadau cywir a chyd-destunol ystyrlon. Mae hyn yn paratoi'r ffordd ar gyfer posibiliadau ymgysylltu a rhyngweithio arloesol â'ch cynnwys gweledol ar gyfer eich cynulleidfa.

Hyfforddiant Gwasanaethau Testun-i-Leferydd
Rydym yn darparu set ddata helaeth sy'n cynnwys recordiadau sain lleferydd dynol, sy'n ddelfrydol ar gyfer hyfforddi modelau AI. Mae'r modelau hyn yn gallu cynhyrchu lleisiau naturiol a deniadol ar gyfer eich cymwysiadau, gan ddarparu profiad sain unigryw a throchi i'ch defnyddwyr.



